當我們在 Google 搜尋引擎輸入 The most incredible 時,系統會推薦你高熱度的關鍵字: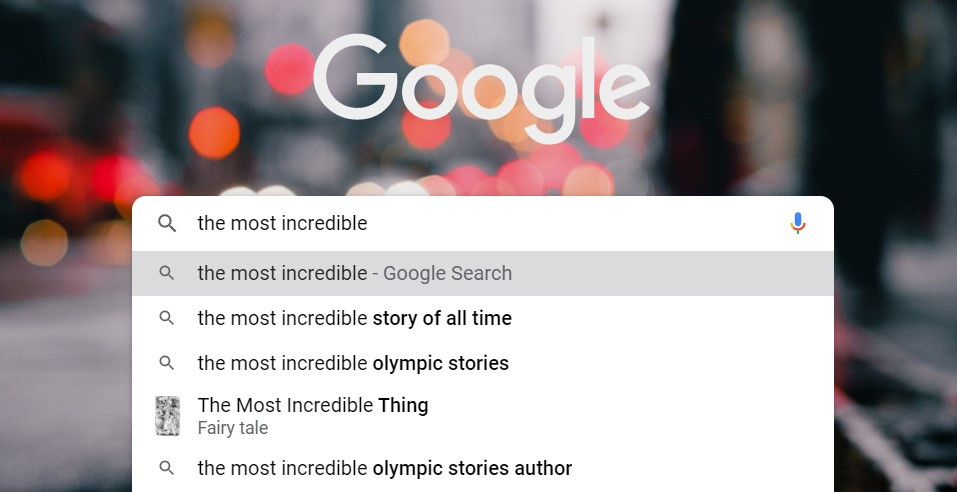
我們不禁產生疑問:系統是如何預測關鍵字的呢?
我們在前一回開頭提到語言模型的定義為描述一個文字序列出現的機率分布,在昨天我們介紹了以單詞出現在語料庫中的頻度作為預測準則的詞袋模型( Bag-of-Words Model ),今天我們聊聊其他的統計語言模型。
根據輸入的句子來預測下一個單詞
圖片來源:A Comprehensive Guide to Build your own Language Model in Python!
試想,這個句子應該下一句會出現什麼單詞?
「 Research shows that both having and deciding how to spend leisure time can be very ... 」
你認為出現 stressful 的機率有多高?[文字出處]
也就是說我們想知道如何估計機率值。
若我們考慮:
則我們將要計算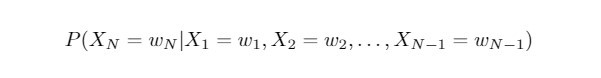
我們基於歷史字串 "Research shows that both having and deciding how to spend leisure time can be very" 來預估當下輸入的單詞 "stressful" 的條件機率。在這裡我們假設馬可夫性質( Markov property )成立,亦即當下任何單詞的出現,僅依賴於前一個單詞。這無疑簡化了我們的問題: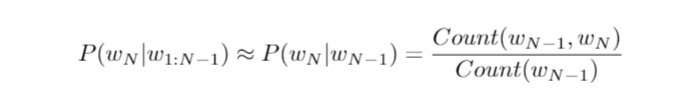
右側的 Count() 指的是計算詞組在語料庫中的個數,分子為 "very stressful" 單詞序列的個數,分母為單詞 "very" 的個數,整體的比值則是 "very stressful" 一起出現的相對頻率( relative frequency )。而計算詞組出現的頻率,則取決於語料庫內單詞或詞組的個數。
不難發現,以上我們的文字預測,只關乎由兩個單詞所連成的字串,這種語言模型被稱為二元語法( bigram model )。而上一篇我們所介紹的詞袋模型,由於只採計單詞出現的次數,與語序、語意、文法皆無關,即是一種單元語法( unigram model )。我們可以推廣這個概念:若當下輸入的單詞,只與過去的 N-1個單詞序列有關,則是為N元語法(N-gram)。以下我們將示範利用三元語法來進行文字預測。
我們來看下列兩個句子:
俄國人說: I love vodka but I hate gin.
英國人說: I love gin but I hate vodka.
我們將上面句子當作小型的語料庫,並利用詞袋模型來表示 gin 與 vodka ,由於兩者出現的次數一致,向量化後的結果並無二致,因此必須選用 N≥2 的N-gram model。
由於時間關係,今天我未能詳細介紹 N-gram Models 的 Python 實際應用。明天我將會示範如何利用這個統計模型來進行文字預測,じゃあね!


